Simply put, a predictive model in healthcare aims to learn the associations between the input data attributes and the target outcome so that the learned associations could be used to predict the actual outcome for a new patient. This post aims to educate you on how to develop a predictive model, with relevance to healthcare.
The image below shows a general framework/steps used to build and validate a predictive model. These steps are generic and are used most commonly to develop predictive models. However, there are other ways to develop them as well and they will not be the content of this post.
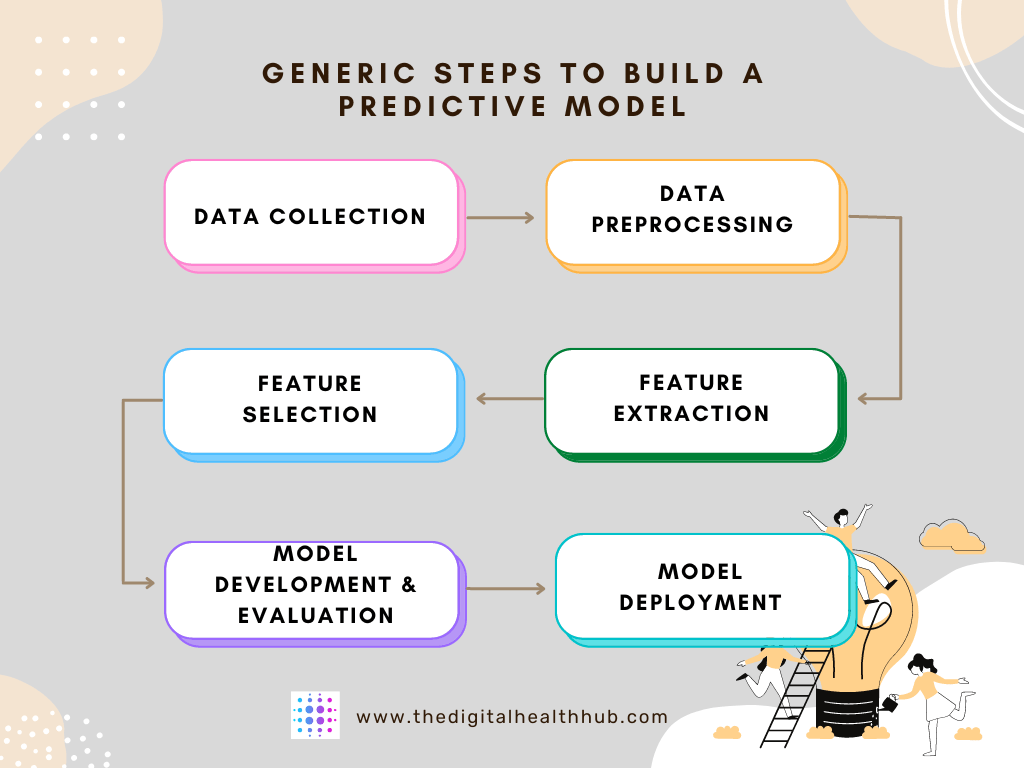
Step 1: Data Collection
To collect good quality data, it is essential to ensure:
(i) data completeness: e.g. ensure that there are fewer missing values recorded from sensors, a smaller number of missing attributes in EHRs, EMRs, etc.
(ii) data consistency: e.g. ensure that the data does not have discrepancies in medical codes or attribute names, etc.
(iii) data relevance: collect only the data that are relevant to the project at hand, and therefore domain knowledge is essential
(iv) data privacy: ensure that the data collected conforms to the Health Insurance Portability and Accountability Act (HIPAA) and other relevant data privacy regulations

Step 2: Data Collection
Data collection is an expensive and time-consuming task in the healthcare field!
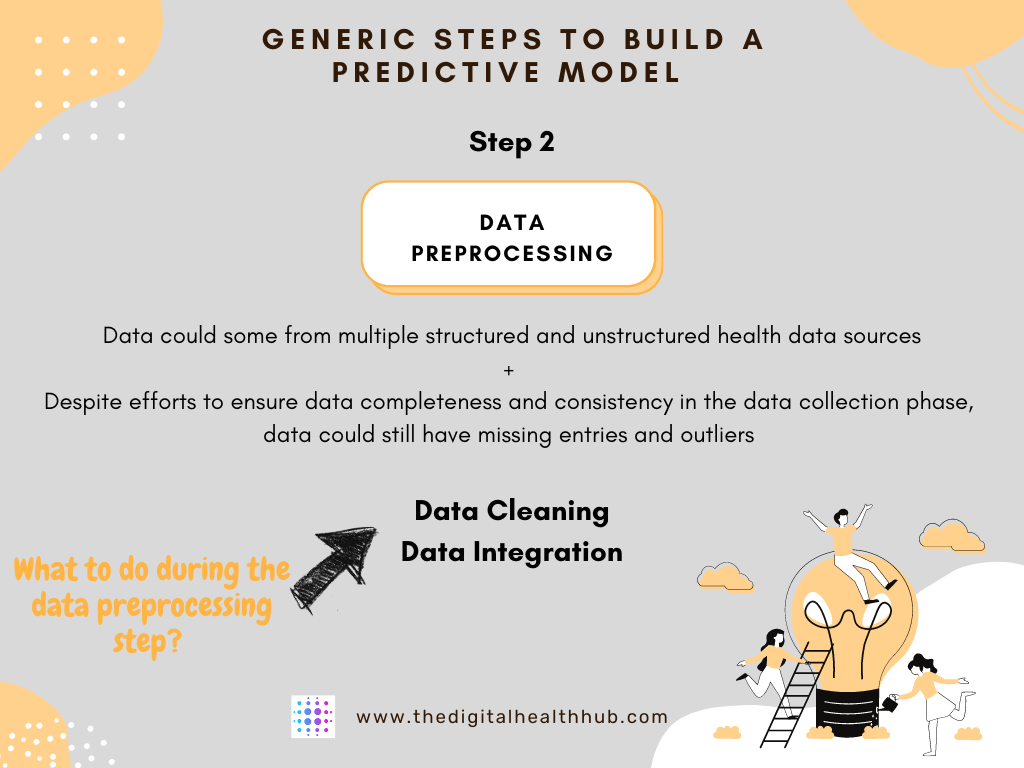
For some projects, extensive clinical trials are required to acquire the necessary data in standardized settings. When data is obtained, they are often not in a form that is suitable for further analysis. Data might be collected from varied structured (e.g., EMRs, EHRs) and unstructured (e.g., radiology images, physician notes) sources that need to be appropriately integrated. Moreover, data could still have missing entries and outliers.
Data preprocessing consists of the steps taken for data cleaning and data integration.
Step 3: Feature Extraction
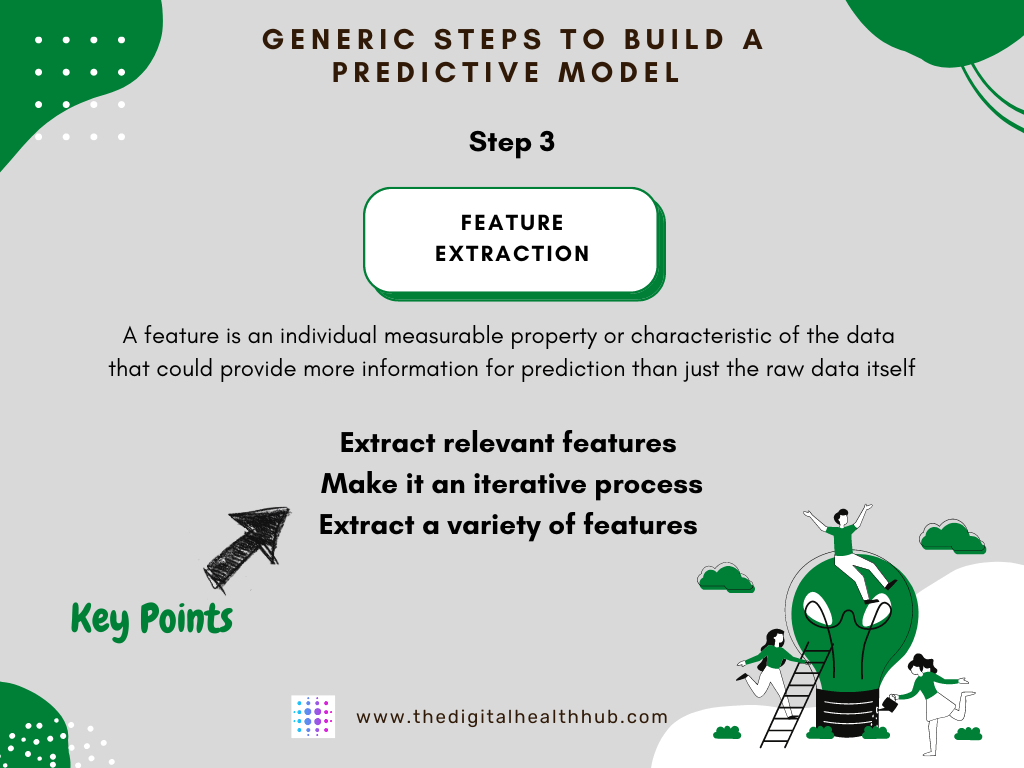
Feature extraction is a time-consuming step in predictive modeling, but an important one. Raw data is not always usable as it is in algorithms.
Example features from healthcare data:
1. Radiomics: extract a large number of quantitative features from medical images using data characterization algorithms.
2. Extract statistical or non-linear features from signals such as ECG, EEG.
Key points:
1. Extract relevant features: Retain only the features relevant to the project goal. e.g. only the lab results that are actually relevant to the goal.
2. Make feature extraction iterative: build an initial set of features, do some analyses, determine useful features, build additional subsets of features, and so on.
3. Extract a variety of features to capture patterns in the raw data more effectively: temporal, statistical, non-linear, image-based, data-transformation-based, etc.
Step 4: Feature Selection
Obtaining a smaller set of representative features and retaining the optimal salient characteristics of the data decreases the processing time and leads to more compactness of the predictive models learned, better generalization, and comprehensibility of the mined results.

Step 5: Model Development & Evaluation
In this step, any one or a combination of the below predictive models (listed in the image) is built by training the models to associate the predictive features with the target outcome. We could write our own algorithm from scratch or feed the data into one or more of several built in algorithms in any software library (Python, R, etc.) to build the model. For this purpose, generally, the original dataset is resampled to form training and test datasets. The training dataset is used for the model building process, and the built model is evaluated using the new unseen test dataset.

Step 6: Model Validation
After deployment, when a new patient data is received, it is first pre-processed to handle missing values or outliers. The predictive features determined as the best during the model development phase are calculated from this patient’s dataset. These features are then fed to the predictive model to determine the outcome for this patient.

If you are interested in learning more on where and how predictive analytics can be employed to improve healthcare, read my latest book. Link here:
Predictive Analytics in Healthcare, Volume 1.
The book
- presents an overview of Predictive A for physicians, medical students, biomedical engineers, and data scientists in the healthcare domain.
- reviews the current applications of analytics in several healthcare disciplines, so that readers specializing in that field can have a comprehensive overview of all methodologies in place.
- enables readers to identify what new applications are needed to advance the use of analytics in their field.


Leave a comment